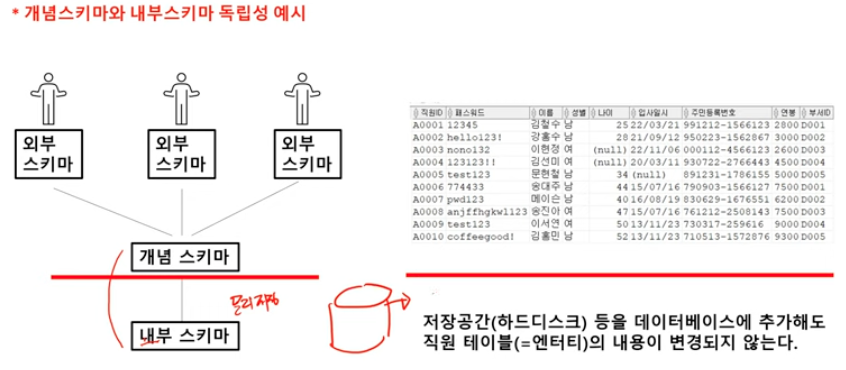
[SQL기본] 01. 관계형 데이터베이스 개요
데이터베이스 관련 용어 정리
- 데이터베이스(DataBase, DB)
- 데이터를 일정한 형태로 저장해 놓은 것 ex)엑셀
- 데이터베이스관리시스템(DataBase Management System, DBMS)
- 기존 데이터베이스 기능에 추가로 데이터 손상을 방지 및 복구, 인증된 사용자만 접근 등 추가 기능을 지원하는 관리 시스템
- 관계형 DBMS (Relational DBMS, RDBMS)
- 테이블로 데이터를 관리하고 테이블간 관계를 이용해 데이터를 정의하는 방식으로, 대부분 기업이 사용하며 지금 공부하는 Oracle도 RDBMS 중 하나임

- 테이블(Table)
- RDBMS에서 실제 데이터가 저장되고 조회되는 2차원 배열 형태의 저장소 공간
- 엔터티, 속성, 인스턴스가 각각 DB가 이해할 수 있는 형태인 테이블, 컬럼, 튜플로 변경된 것

- SQL(Structured Query Language)
- RDBMS에서 데이터 정의, 조작, 조회, 제어 등을 하기 위해 사용하는 언어
- (매우 중요한 내용이니 종류별로 어떤 문법이 있는지 외워야함)
| DDL(Data Definition Language, 데이터 정의어) | CREATE, ALTER, DROP, RENAME, TRUNCATE |
| DML(Data Manipulation Language, 데이터 조작어) | SELECT, INSERT, UPDATE, DELETE, MERGE |
| DCL(Data Control Language, 데이터 제어어) | GRANT, REVOKE |
| TCL(Transaction Control Language, 트랜잭션 제어어) | COMMIT, ROLLBACK, SAVEPOINT |
STANDARD SQL 개요
일반집합연산자와 순수관계연산자

[SQL기본] 02. SELECT문
SELECT란?
:테이블에서 원하는 데이터를 조회할 때 사용하는 문법
SELECT CUST_ID, CUST_NAME, BIRTH_DY
FROM TB_CUST
WHERE MONEY = 10000;
1. TB_CUST 테이블에서(FROM) 데이터를 가져오겠습니다.
2. TB_CUST 테이블에서 MONEY (보유금액)이 10000인 튜플(행)만 가져오겠습니다.
3. 출력되는 튜플(행)에 대해 CUST_ID, CUST_NAME, BIRTH_DY 컬럼(열)만 가져오겠습니다.
SELECT *FROM TB_PRD;
TB_PRD 테이블의 모든 컬럼 정보를 출력합니다.
==> *(애스터리스크)는 SELECT뒤에 사용되며 테이블 내의 모든 컬럼 정보를 출력함.
SELECT DISTINCT PRD_TYPE FROM TB_PRD;
TB_PRD 테이블의 PRD_TYPE 컬럼을 기준으로 값을 중복없이 출력합니다.
==> DISTINCT는 SELECT 뒤, 컬럼 앞에 사용되며 해당 컬럼 정보에 대해 중복을 제거함.
==> AS는 SELECT 부분에서 출력하려는 컬럼에 대해 새로운 별명(ALIAS)를 부여할 수 있음.
AS 사용시 주의사항
1. 띄어쓰기 불가
2. 문자로 시작 해야함
3. 예약어 불가
4. 특수문자는 $, _, # 만 가능

SELECT에서 연결연산하기 ( || 기호 사용하기 )

SELECT에서 사칙연산하기

'데이터베이스 > SQL 개발자 이론' 카테고리의 다른 글
| 04. 속성과 도메인 (0) | 2024.08.19 |
|---|---|
| [1과목] 01. 데이터모델링 (1) | 2024.08.19 |
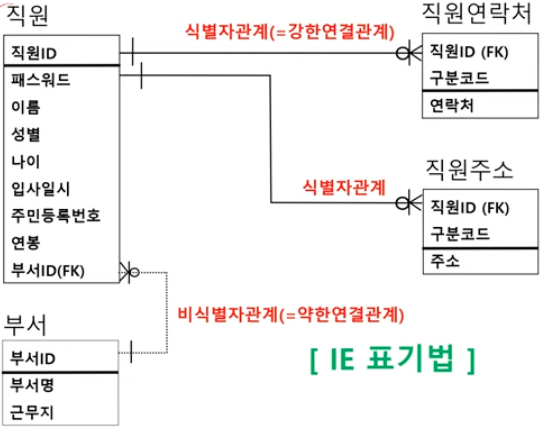
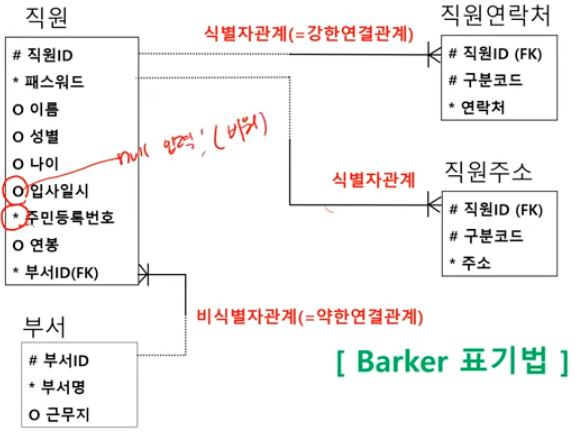
| [1과목] 데이터 모델과 SQL - 05. 본질식별자 vs 인조식별자 (0) | 2024.07.27 |
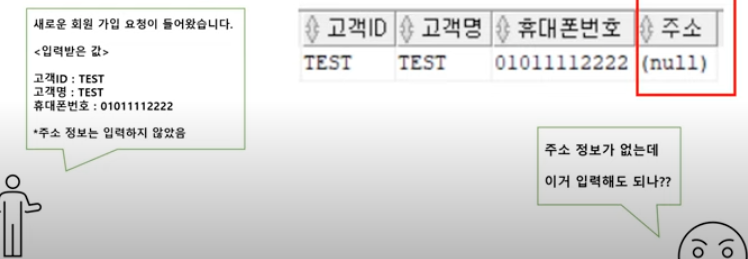
| [1과목] 데이터 모델과 SQL - 04. NULL 속성의 이해 (0) | 2024.07.27 |
| [1과목] 데이터 모델과 SQL - 03. 모델이 표현하는 트랜잭션의 이해 (0) | 2024.07.27 |