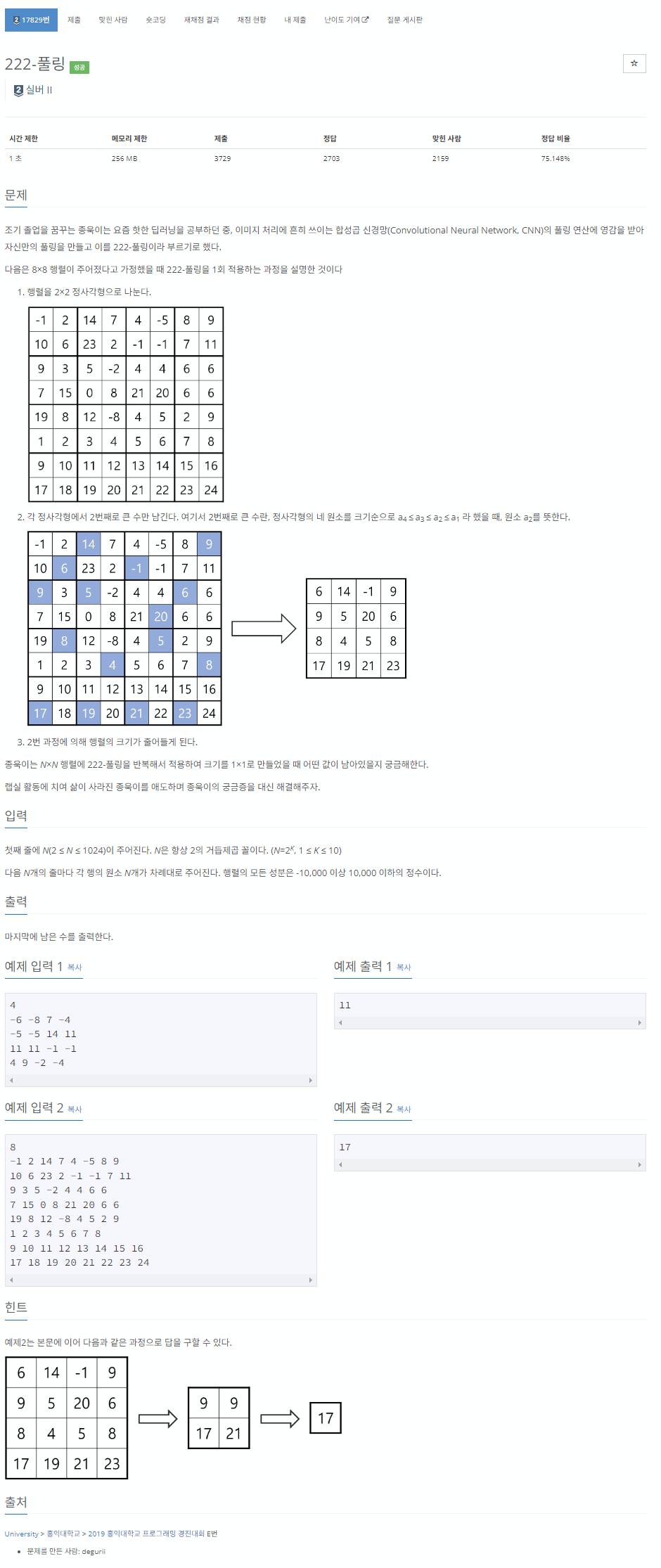
5-1. 배열 개념
배열은 인덱스와 값을 1대 1 대응하여 관리하는 자료구조이다.
배열은 인덱스를 통해 어떤 위치에 있는 값이든 한 번에 접근할 수 있다.
이런 방식을 임의 접근(random access)라고 한다.
파이썬에서 배열 선언하는 방법
arr = [0, 0, 0]
arr = [0] * 3
리스트 생성자를 사용하는 방법
arr = list(range(3)) #[0, 1, 2]
리스트 컴프리헨션을 활용하는 방법
arr = [0 for _ in range(3)] # [0, 0, 0]
파이썬에서는 배열을 지원하는 문법은 따로 없고, 대신 리스트라는 문법을 지원한다.
(사실 엄밀히 말하자면 배열과 리스트는 다른 개념임)
파이썬의 리스트는 동적으로 크기를 조절할 수 있도록 구현됐다.
파이썬의 리스트는 다른 언어의 배열 기능을 그대로 사용하면서 배열의 크기는 가변적으로 사용할 수 있다.
배열과 차원
배열은 2차원, 3차원, ..., 다차원 배열 까지 사용할 수 있다.
그러나 컴퓨터의 메모리 구조는 1차원이다.
이는 2차원, 3차원, ..., 다차원 배열도 실제로는 1차원 공간에 저장된다는 뜻이다.
배열은 몇 차원이든 상관없이 메모리에는 연속적으로 할당된다.
1차원 배열
배열의 각 데이터는 메모리의 낮은 주소에서 높은 주소 방향으로 연속적으로 할당된다.
2차원 배열
2차원 배열은 1차원 배열을 확장한 것이다.
2차원 배열 활용 예시
# 2차원 배열을 리스트로 표현
arr = [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]
# arr[2][3]에 저장된 값 출력
print(arr[2][3]) # 12
# arr[2][3]에 저장된 값을 15로 변경
print[2][3] = 15
리스트 컴프리헨션을 통한 2차원 배열 활용 예시
# 크기가 3 * 4인 리스트를 선언하는 예시
arr = [[i]*4 for i in range(3)] # [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]
arr = [[1, 2, 3], [4, 5, 6]]
위의 배열에서 첫번째 행과 두번째 행의 메모리 주소는 연속된다. (1행의 인덱스 2 다음 바로 2행의 인덱스0의 주소가 이어진다. )
5-2. 배열의 효율성
배열 연산의 시간복잡도를 통해 배열의 효율성은 아래와 같다.
배열 연산의 시간 복잡도
아까 배열은 인덱스를 통해 임의 접근 방법을 사용한다고 했다. 따라서 데이터에 접근하기 위한 시간 복잡도는 O(1)이다.
만약 배열에 데이터를 추가하거나 삭제해야 한다면? 추가후에 기존에 있던 것들을 처리할 필요가 있는지, 혹은 대상을 삭제하고 기존에 있는 것들을 처리할 필요가 있는지 확인이 필요하다.
1. 맨 뒤에 삽입할 경우
- 임의 접근을 통해 맨뒷 자리를 찾을 수 있다.
- 맨 뒤에 값을 추가한 후에 기존의 값들을 이동할 필요가 없다.
- 즉, 시간 복잡도는 O(1)이다.
2. 맨 앞에 삽입할 경우
- 임의 접근을 통해 맨 앞 자리를 찾을 수 있다.
- 기존 데이터 들을 뒤로 한칸씩 밀어야 데이터의 소실 없이 맨 앞에 값을 삽입할 수 있다. (== 현재 갖고 있는 데이터의 개수가 N개라면, O(N))
- 즉, 시간 복잡도는 O(N)이다.
3. 중간에 삽입할 경우
- 임의 접근을 통해 중간에 삽입할 자리를 찾을 수 있다.
- 기존 데이터 들을 뒤로 한칸씩 밀어야 데이터의 소실 없이 맨 앞에 값을 삽입할 수 있다. (== 뒤로 밀어야 야 하는 데이터의 개수가 N개라면, O(N))
- 즉, 시간 복잡도는 O(N)이다.
위의 경우 들을 봤을때, 배열로 데이터를 저장하기 전에는 항상 이런 비용을 생각하는 것이 바람직하다.
이렇듯 배열을 선택할 때 고려할 점은 다음과 같다.
배열을 선택할 때 고려할 점
1. 할당할 수 있는 메모리 크기를 확인해야 한다. (파이썬에서는 리스트를 사용하므로, 배열 크기에 대한 고민은 할 필요가 없다. 공부를 위해 읽어두기)
- 운영체제마다 배열을 할당할 수 있는 메모리의 값은 다르지만, 보통 정수형 1차원 배열은 1천 만개, 2차원 배열은 3천*3천 크기를 최대로 생각한다. 따라서 이 이상의 값의 데이터를 관리하고자 하면 런타임에서 배열 할당에 실패할 수 있다.
2. 중간에 데이터 삽입이 많은지 확인해야 한다.
- 배열은 선형 자료구조이기 때문에, 중간이나 맨 처음의 위치에 데이터를 자주 삽입하면 시간복잡도가 높아져, 시간초과가 발생할 수 있다.
5-3. 코딩테스트에서 자주 활용하는 리스트 기법
리스트에 데이터를 추가하는방법
1. append()
# 리스트의 맨 끝에 데이터 추가
tmp_list = [1, 2, 3]
tmp_list.append(4) # [1, 2, 3, 4]
2. + 연산자
tmp_list = [1, 2, 3]
tmp_list = tmp_list + [4, 5] # [1, 2, 3, 4, 5]
3. insert()
# 특정 위치에 데이터를 삽입할 수 있다.
tmp_list = [1, 2, 3]
tmp_list.insert(2, 9) #[1, 2, 9, 3]
리스트에서 데이터를 삭제하는 방법
1. pop()
# 특정 위치에 데이터를 삭제할 수 있다.
# 삭제한 데이터의 값을 반환한다.
tmp_list = [1, 2, 3]
pop = tmp_list.pop(2) # 3
print(tmp_list) # [1, 2]
2. remove()
# 특정 데이터를 찾아 삭제할 수 있다.
# 인수로 받은 값이 처음 등장하는 위치의 데이터를 삭제한다.
tmp_list = [1, 2, 3]
tmp_list.remove(2) # [1, 3]
리스트 컴프리헨션으로 데이터에 특정 연산 적용하기
리스트 컴프리헨션은 기존 리스트를 기반으로 새 리스트를 만들거나, 반복문이나 조건문을 통해 복잡한 리스트를 생성하는 등 다양한 상황에서 사용할 수 있는 문법이다.
리스트에 제곱 연산 적용 예시
tmp_list = [1, 2, 3]
squares = [num**2 for num in tmp_list] #[1, 4, 9]
# tmp_list의 값은 여전히 [1, 2, 3] 이다.
리스트 컴프리헨션은 연산이 끝난 리스트를 반환할 뿐, 연산 대상 리스트를 바꾸지 않는다.
유용하게 쓰이는 리스트 연관 메서드
alphabet = ["a", "b", "c", "a"]
# 리스트의 전체 데이터 개수 반환 함수 len()
len(alphabet) # 4
# 특정 데이터가 처음 등장할 적의 인덱스를 반환하는 index()메서드, 만약 값이 없는경우 -1 반환
alphabet.index("a") # 0
# 사용자가 정한 기준에 따라 데이터를 정렬하는 sort()메서드
# 함수안에 인수가 없을 경우, 오름차순으로 데이터 정렬
alphabet.sort() # ["a", "a", "b", "c"]
# 역순
alphabet.sort(reverse=True) # ["c", "b", "a", "a"]
# 특정 데이터 개수를 반환하는 count() 메서드
alphabet.count("a") # 2
* 정리된 개념 출처: 코딩 테스트 합격자 되기 - 박경록(파이썬 편)
'코딩테스트 > 자료 구조 및 알고리즘' 카테고리의 다른 글
| [코딩테스트] No.5 큐-7장 (1) | 2024.09.15 |
|---|---|
| [코딩테스트] No.4 스택-6장 (0) | 2024.09.07 |
| [코딩테스트] No.2 코딩 테스트 필수 문법(파이썬)-4장 (0) | 2024.08.25 |
| [코딩테스트] No.1 알고리즘 효율 분석(시간복잡도)-3장 (0) | 2024.08.17 |
| [알고리즘] LCS(Longest Common Subsequence) (0) | 2024.08.14 |